
Ao final deste guia você será capaz de projetar arquiteturas de agentes multi-passo com delegação, safety e métricas claras usando Hermes + MCP. No meu sistema, os guias da Anthropic + OpenAI + minha prática viram método para construir agentes efetivos que crescem — autonomia real, sem hype.
Quando isso é para você (nível Intermediário): quem já roda workflows ou MCP e quer escalar para arquiteturas confiáveis sem cair em anti-padrões complexos demais cedo.
Nos últimos meses, dois guias se tornaram referência obrigatória para quem constrói agentes de IA: o "Building Effective Agents" da Anthropic e o "A Practical Guide to Building AI Agents" da OpenAI.
Estudei os dois a fundo. Cada um tem uma perspectiva diferente — a Anthropic foca em patterns de composição (como montar workflows), enquanto a OpenAI foca nos fundamentos (modelo, tools, instruções) e em safety. Juntos, eles cobrem praticamente tudo que você precisa saber.
Este post é uma síntese do que aprendi, combinada com experiência prática no meu sistema.
Sumário executivo — Agentes de IA efetivos são sistemas que loopam entre percepção, raciocínio e ação, não chatbots com tools. Os 3 pilares são: modelo suficientemente capaz, tools bem projetadas e instruções claras. A arquitetura deve começar simples (workflow determinístico), só escalar para multi-agent quando houver clara separação de responsabilidades. Safety não é opcional: inclua guardrails de input, output e controle, com human-in-the-loop em decisões de alto risco. Métricas essenciais: Task Success Rate, Task Latency, Tool Error Rate e human-feedback score. O post inclui código prático com Hermes Agent.
Vou cobrir:
- Os 3 pilares de um agente (modelo, tools, instruções)
- Os 5 patterns de arquitetura para compor workflows
- Single-Agent vs. Multi-Agent: quando escalar
- Safety e Guardrails: o que ninguém quer implementar mas todo mundo precisa
- Anti-patterns e métricas para saber se está funcionando
- Código prático usando Hermes Agent
O que é um agente (de verdade)
Antes de qualquer pattern, precisamos de uma definição clara. Um agente de IA não é um chatbot com acesso a tools. É um sistema que:
- Recebe uma tarefa de alto nível
- Toma decisões autônomas sobre como executá-la
- Usa ferramentas (tools) como meio, não como fim
- Itera com base em feedback do ambiente
Um chatbot que responde "qual o clima?" usando uma tool de previsão do tempo não é um agente — é um sistema reativo. Um agente receberia "organize minha viagem para o fim de semana", decidiria sozinho que precisa verificar o clima, buscar voos, reservar hotel, e iteraria se algum voo estiver esgotado.
A diferença é autonomia de orquestração. O agente decide o plano, não apenas executa um plano pré-definido.
Exemplo de configuração de um agente no arquivo config.yaml do Hermes Agent.
O que dizem os guias
Os dois guias convergem em uma tese central: comece simples e adicione complexidade apenas quando os dados justificarem.
A Anthropic foca em patterns de composição:
- A maioria dos sistemas de IA efetivos não são agentes monolíticos, mas workflows compostos por patterns reutilizáveis
- Workflows (passos pré-definidos) são melhores para tarefas previsíveis
- Agentes (autonomia de decisão) são melhores para tarefas abertas e dinâmicas
- Propõe 5 patterns que cobrem 90% dos casos de uso
A OpenAI foca nos fundamentos e em produção:
- Todo agente se reduz a 3 componentes: Modelo, Tools e Instruções
- Comece com um único agente — só escale para multi-agent quando necessário
- Safety não é opcional: classifiers, PII filters, human-in-the-loop desde o dia 1
- Comece com o modelo mais capaz, depois otimize para custo e latência
Vamos combinar os dois frameworks, começando pelos fundamentos.
Execução de um agente via terminal com hermes run --agent — cada execução gera logs estruturados.
Os 3 pilares de um agente
A OpenAI estrutura todo agente em torno de 3 componentes fundamentais. Parece simples, mas acertar cada um faz toda a diferença entre um agente que funciona e um que alucina.
Pilar 1: Modelo
O modelo é o "cérebro" do agente. A regra mais contra-intuitiva do guia da OpenAI:
Comece com o modelo mais capaz disponível. Estabeleça um baseline de qualidade, depois teste modelos menores para otimizar custo e latência.
Na prática, isso significa:
| Fase | Modelo | Objetivo |
|---|---|---|
| Prototipagem | GPT-4o / Claude Sonnet | Validar que a tarefa é viável |
| Otimização | GPT-4o-mini / Claude Haiku | Reduzir custo mantendo qualidade |
| Produção | O menor que passe nos testes | Custo/latência otimizados |
A tentação é começar com o modelo mais barato "para economizar". O problema: você não sabe se os erros são do modelo ou da sua arquitetura. Comece capaz, otimize depois.
Pilar 2: Tools
Tools são as mãos do agente — como ele interage com o mundo real. Um agente sem tools é só um chatbot eloquente.
Boas práticas para design de tools:
- Nomes descritivos:
buscar_pedido_por_id>get_data. O modelo usa o nome para decidir quando chamar a tool - Descrições claras: Documente o que a tool faz, quais parâmetros aceita, e o que retorna
- Schemas estruturados: Use JSON Schema para parâmetros — reduz erros de parsing
- Granularidade adequada: Nem tools genéricas demais (
fazer_tudo) nem específicas demais (buscar_nome_do_cliente_por_email_no_banco_postgres) - Erros informativos: Retorne mensagens de erro que ajudem o modelo a se corrigir
# ❌ Tool mal projetada
@tool
def query(q: str) -> str:
"""Faz uma query."""
return db.execute(q)
# ✅ Tool bem projetada
@tool
def buscar_pedidos_cliente(
cliente_id: str,
status: str = "todos",
limite: int = 10
) -> list:
"""Busca pedidos de um cliente específico.
Args:
cliente_id: ID único do cliente (ex: 'cli_abc123')
status: Filtro por status - 'pendente', 'enviado', 'entregue' ou 'todos'
limite: Máximo de pedidos retornados (1-50)
Returns:
Lista de pedidos com id, data, valor e status.
Retorna lista vazia se cliente não encontrado.
"""
return db.pedidos.find(cliente_id=cliente_id, status=status, limit=limite)
Pilar 3: Instruções
Instruções são as regras do jogo. O system prompt define como o agente deve se comportar, não apenas o que fazer.
Anatomia de um bom system prompt:
1. PAPEL — Quem o agente é
2. OBJETIVO — O que ele deve alcançar
3. REGRAS — Limites e comportamentos obrigatórios
4. FORMATO — Como estruturar a resposta
5. EXEMPLOS — Few-shot para casos ambíguos
6. EDGE CASES — O que fazer quando der errado
Exemplo prático:
system_prompt = """
Você é um assistente de suporte técnico da Acme Corp.
OBJETIVO: Resolver problemas técnicos dos clientes de forma autônoma.
REGRAS:
- SEMPRE consulte a base de conhecimento antes de responder
- NUNCA invente informações técnicas — se não sabe, diga "vou escalar"
- Se o problema envolve dados financeiros, escale para humano imediatamente
- Limite de 3 tentativas de resolução antes de escalar
FORMATO:
- Comece identificando o problema
- Liste os passos de resolução
- Confirme com o cliente antes de executar ações
EXEMPLOS:
Usuário: "Meu login não funciona"
Ação: 1) buscar_usuario(email) 2) verificar_status_conta 3) resetar_senha se necessário
Edge case: Se o cliente estiver irritado, reconheça a frustração antes de investigar.
"""
Esses 3 pilares parecem básicos, mas na prática a maioria dos agentes falha por tools mal nomeadas, instruções vagas, ou modelo subdimensionado. Acerte os pilares antes de pensar em patterns.
Exemplo de configuração de um agente no arquivo config.yaml do Hermes Agent.
Comece simples, evolua com dados
Antes de mergulhar nos patterns de arquitetura, uma regra que ambos os guias repetem:
Um prompt bem escrito com tools geralmente resolve. Não comece com agentes.
A OpenAI vai além: recomenda começar com um único agente e só escalar para multi-agent quando houver evidência clara de que um agente não dá conta. A Anthropic ecoa: cada pattern adiciona latência, custo e pontos de falha.
Na prática, siga este fluxo:
- Prompt + Tools → Resolve? Pare aqui.
- Um agente com loop → Precisa de iteração? Use um agente simples.
- Workflow com patterns → Precisa de composição? Agora sim, escolha um pattern.
- Multi-agent → Precisa de coordenação complexa? Último recurso.
Os 5 patterns de arquitetura
A Anthropic propõe 5 patterns de composição que cobrem a maioria dos workflows de agentes. Vou apresentar cada um com implementação prática.
Pattern 1: Prompt Chaining
O que é
Decompor uma tarefa complexa em sub-tarefas sequenciais, onde a saída de cada passo alimenta o próximo. É o equivalente a uma pipeline de processamento.
Quando usar
- A tarefa tem etapas bem definidas e dependentes
- Você precisa de validação intermediária
- A saída de um passo precisa ser transformada antes do próximo
Quando NÃO usar
- As etapas são independentes (use Parallelization)
- A tarefa é simples o suficiente para um único prompt
- Latência é crítica (cada passo adiciona tempo de LLM)
Diagrama
Implementação com Hermes Agent
from hermes_agent import Agent, tool
import json
class EmailProcessor:
"""Pipeline de processamento de email usando Prompt Chaining."""
def __init__(self):
self.extractor = Agent(
model="claude-3-5-sonnet-20241022",
system="""Extraia do email: remetente, assunto, intenção principal,
e dados estruturados mencionados. Retorne apenas JSON válido."""
)
self.analyzer = Agent(
model="claude-3-5-sonnet-20241022",
system="""Analise os dados extraídos de um email e classifique:
- prioridade: alta/media/baixa
- categoria: suporte/vendas/financeiro/outro
- necessita_resposta: true/false
Retorne apenas JSON válido."""
)
self.formatter = Agent(
model="claude-3-5-sonnet-20241022",
system="""Formate a análise em um resumo executivo de 2-3 linhas
com ação recomendada."""
)
async def process(self, email_body: str) -> dict:
# Passo 1: Extração
raw_extract = await self.extractor.run(email_body)
extracted = json.loads(raw_extract)
# Passo 2: Análise (recebe saída do passo 1)
raw_analysis = await self.analyzer.run(json.dumps(extracted))
analysis = json.loads(raw_analysis)
# Passo 3: Formatação (recebe saída do passo 2)
summary = await self.formatter.run(json.dumps(analysis))
return {
"extracted": extracted,
"analysis": analysis,
"summary": summary,
"action": analysis.get("necessita_resposta", False)
}
Comparação: Agente Monolítico
Um agente monolítico receberia o email e tentaria fazer tudo de uma vez. O problema:
- Hallucination aumentada: Mais tarefas = mais chance de erro
- Difícil debugar: Se a prioridade estiver errada, onde foi o erro?
- Inflexível: Não consigo reutilizar o extrator para outro pipeline
O chaining resolve isso com separação de responsabilidades e validação intermediária.
Pattern 2: Routing
O que é
Direcionar um input para o handler especializado correto com base em sua classificação. É um switch inteligente.
Quando usar
- Você tem múltiplos domínios/specialistas
- O input varia muito em tipo ou intenção
- Cada domínio precisa de contexto e tools diferentes
Quando NÃO usar
- Todos os inputs são homogêneos
- A classificação é trivial (use um if simples)
- O overhead de múltiplos agents não justifica o ganho
Diagrama
Implementação com Hermes Agent
from hermes_agent import Agent, tool
from enum import Enum
class Department(Enum):
SUPPORT = "suporte"
SALES = "vendas"
TECHNICAL = "tecnico"
class SmartRouter:
"""Sistema de roteamento inteligente de atendimento."""
def __init__(self):
self.router = Agent(
model="claude-3-5-haiku-20241022", # Router pode ser mais leve
system="""Classifique a mensagem do cliente em uma categoria:
- suporte: problemas, reclamações, dúvidas de uso
- vendas: orçamentos, interesse em produtos, upgrades
- tecnico: bugs, integração API, erros de sistema
Retorne APENAS a categoria, sem explicação."""
)
self.handlers = {
Department.SUPPORT: Agent(
model="claude-3-5-sonnet-20241022",
system="Você é um especialista em suporte ao cliente...",
tools=[self.search_faq, self.create_ticket]
),
Department.SALES: Agent(
model="claude-3-5-sonnet-20241022",
system="Você é um consultor de vendas...",
tools=[self.check_pricing, self.schedule_demo]
),
Department.TECHNICAL: Agent(
model="claude-3-5-sonnet-20241022",
system="Você é um engenheiro de suporte técnico...",
tools=[self.query_logs, self.check_api_status]
),
}
@tool
async def search_faq(self, query: str) -> str:
"""Busca na base de conhecimento."""
# Implementação real aqui
return "FAQ result..."
@tool
async def check_pricing(self, plan: str) -> str:
"""Retorna preços do plano."""
return f"Preços para {plan}..."
@tool
async def query_logs(self, error_id: str) -> str:
"""Consulta logs de erro."""
return f"Logs para {error_id}..."
async def handle(self, message: str) -> str:
# Passo 1: Classificar
category_str = await self.router.run(message)
category = Department(category_str.strip().lower())
# Passo 2: Rotear para handler especializado
handler = self.handlers[category]
response = await handler.run(message)
return response
Comparação: Agente Monolítico
Um único agente com todas as tools de suporte, vendas e técnico:
- Confunde contextos: Pode oferecer desconto em um bug crítico
- Prompt gigante: System prompt com regras de 3 departamentos
- Custo desnecessário: Carrega contexto de vendas para ticket técnico
O routing mantém cada agente focado e enxuto.
Pattern 3: Parallelization
O que é
Processar múltiplos inputs ou tarefas simultaneamente, agregando os resultados no final. É o oposto do chaining.
Quando usar
- As subtarefas são independentes
- Você precisa de múltiplas perspectivas (votação, revisão)
- Latência é crítica (paralelo é mais rápido que sequencial)
Quando NÃO usar
- As tarefas dependem uma da outra
- O custo de N chamadas paralelas é proibitivo
- Você precisa de estado compartilhado entre passos
Diagrama
Implementação com Hermes Agent
import asyncio
from hermes_agent import Agent
class CodeReviewPanel:
"""Revisão de código paralela com múltiplos especialistas."""
def __init__(self):
self.security_reviewer = Agent(
model="claude-3-5-sonnet-20241022",
system="""Você é um especialista em segurança.
Analise o código para: SQL injection, XSS, secrets expostos,
validação de input ausente. Retorne findings em bullet points."""
)
self.performance_reviewer = Agent(
model="claude-3-5-sonnet-20241022",
system="""Você é um especialista em performance.
Analise o código para: N+1 queries, alocação de memória,
complexidade algorítmica, I/O bloqueante."""
)
self.maintainability_reviewer = Agent(
model="claude-3-5-sonnet-20241022",
system="""Você é um especialista em clean code.
Analise para: duplicação, nomes claros, tamanho de funções,
acoplamento, testabilidade."""
)
self.synthesizer = Agent(
model="claude-3-5-sonnet-20241022",
system="""Sintetize múltiplas revisões em um relatório unificado
com prioridades e ações recomendadas."""
)
async def review(self, code: str) -> str:
# Dispara 3 revisões em paralelo
reviews = await asyncio.gather(
self.security_reviewer.run(code),
self.performance_reviewer.run(code),
self.maintainability_reviewer.run(code),
)
# Agrega resultados
combined = f"""
## Revisão de Segurança
{reviews[0]}
## Revisão de Performance
{reviews[1]}
## Revisão de Manutenibilidade
{reviews[2]}
"""
final_report = await self.synthesizer.run(combined)
return final_report
Comparação: Agente Monolítico
Um único agente fazendo revisão completa:
- Menor qualidade: Especialista generalista vs. 3 especialistas
- Maior latência: Revisão sequencial interna (o LLM processa um aspecto por vez)
- Menor cobertura: Prompt grande dilui a atenção em cada área
O paralelismo garante especialização máxima e latência mínima.
Pattern 4: Orchestrator-Workers
O que é
Um coordenador decompõe uma tarefa complexa, delega subtarefas para workers, e sintetiza os resultados. Diferente do parallelization, o orchestrator decide dinamicamente quais workers usar.
Quando usar
- A tarefa é complexa e o plano não é previsível
- Você precisa de coordenação dinâmica
- Workers precisam de contexto específico do orchestrator
Quando NÃO usar
- O fluxo é sempre o mesmo (use Prompt Chaining)
- Overhead de coordenação não justifica
- Workers são simples o suficiente para serem tools
Diagrama
Implementação com Hermes Agent
import json
import asyncio
from hermes_agent import Agent, tool
from typing import List, Dict
class ReportGenerator:
"""Geração dinâmica de relatórios com Orchestrator-Workers."""
def __init__(self):
self.orchestrator = Agent(
model="claude-3-5-sonnet-20241022",
system="""Você é um orchestrador de relatórios.
Receba um tópico e defina:
1. Quais workers são necessários
2. O que cada worker deve fazer
3. Como combinar os resultados
Retorne um JSON com:
{"workers": [{"name": "...", "task": "..."}], "synthesis_plan": "..."}"""
)
self.workers = {
"research": Agent(
model="claude-3-5-sonnet-20241022",
system="Pesquise dados e estatísticas sobre o tópico."
),
"analysis": Agent(
model="claude-3-5-sonnet-20241022",
system="Analise dados e identifique padrões e tendências."
),
"write": Agent(
model="claude-3-5-sonnet-20241022",
system="Escreva seções de relatório em português formal."
),
"critic": Agent(
model="claude-3-5-sonnet-20241022",
system="Revise e identifique gaps ou imprecisões."
),
}
async def generate(self, topic: str) -> str:
# Passo 1: Orchestrator planeja
plan_json = await self.orchestrator.run(topic)
plan = json.loads(plan_json)
# Passo 2: Executa workers em paralelo conforme plano
worker_tasks = []
for worker_spec in plan["workers"]:
worker = self.workers[worker_spec["name"]]
task = worker.run(f"Tópico: {topic}\nTarefa: {worker_spec['task']}")
worker_tasks.append(task)
results = await asyncio.gather(*worker_tasks)
# Passo 3: Síntese final
synthesis_input = f"""
Plano de síntese: {plan['synthesis_plan']}
Resultados dos workers:
{chr(10).join(f"--- {w['name']} ---{chr(10)}{r}" for w, r in zip(plan['workers'], results))}
"""
final_report = await self.workers["write"].run(synthesis_input)
return final_report
Comparação: Agente Monolítico
Um único agente gerando um relatório:
- Não escala: Relatórios maiores excedem context window
- Sem especialização: Mesmo modelo escrevendo e pesquisando
- Sem paralelismo: Tudo sequencial, latência alta
O orchestrator permite escala dinâmica e especialização por worker.
Pattern 5: Evaluator-Optimizer
O que é
Um loop de feedback: gera uma resposta, avalia sua qualidade, e refina até atingir um critério. É o pattern mais próximo de "agente autônomo".
Quando usar
- Qualidade é mais importante que latência
- Existem critérios objetivos de qualidade
- A tarefa beneficia de iteração (escrita, design, código)
Quando NÃO usar
- Latência é crítica (cada iteração = 1+ chamada de LLM)
- Não há critérios claros de "bom o suficiente"
- O custo de múltiplas iterações é proibitivo
Diagrama
Implementação com Hermes Agent
import json
from hermes_agent import Agent
from dataclasses import dataclass
@dataclass
class Evaluation:
score: float # 0.0 a 1.0
passed: bool
feedback: str
suggestions: list
class IterativeRefiner:
"""Refinamento iterativo com Evaluator-Optimizer."""
def __init__(self, max_iterations: int = 3, threshold: float = 0.85):
self.max_iterations = max_iterations
self.threshold = threshold
self.generator = Agent(
model="claude-3-5-sonnet-20241022",
system="""Você é um escritor técnico.
Escreva ou refine conteúdo com base no feedback fornecido.
Retorne apenas o conteúdo final, sem metadados."""
)
self.evaluator = Agent(
model="claude-3-5-sonnet-20241022",
system="""Você é um editor rigoroso.
Avalie o conteúdo em:
- Clareza (0-1)
- Precisão técnica (0-1)
- Completeza (0-1)
- Tom adequado (0-1)
Retorne JSON:
{"score": float, "passed": bool, "feedback": str, "suggestions": [str]}"""
)
async def refine(self, prompt: str, initial_content: str = None) -> dict:
content = initial_content or await self.generator.run(prompt)
history = []
for iteration in range(self.max_iterations):
# Avalia
eval_json = await self.evaluator.run(
f"Prompt original: {prompt}\n\nConteúdo:\n{content}"
)
evaluation = Evaluation(**json.loads(eval_json))
history.append({"iteration": iteration, "score": evaluation.score})
if evaluation.passed or evaluation.score >= self.threshold:
return {
"content": content,
"iterations": iteration + 1,
"final_score": evaluation.score,
"history": history
}
# Refina com feedback
refinement_prompt = f"""
Prompt original: {prompt}
Conteúdo atual:
{content}
Feedback do avaliador:
{evaluation.feedback}
Sugestões:
{chr(10).join(f"- {s}" for s in evaluation.suggestions)}
Por favor, refine o conteúdo incorporando o feedback."""
content = await self.generator.run(refinement_prompt)
return {
"content": content,
"iterations": self.max_iterations,
"final_score": evaluation.score,
"history": history,
"maxed_out": True
}
Comparação: Agente Monolítico
Um único passo de geração:
- Qualidade inconsistente: Sem garantia de atingir critérios
- Sem feedback loop: Erros não são corrigidos
- Prompts gigantes: Tentar embutir todos os critérios no system prompt
O evaluator-optimizer garante qualidade mínima com custo controlado (max_iterations).
Single-Agent vs. Multi-Agent
A OpenAI dedica uma seção inteira a esta decisão, e o conselho é claro: comece com um único agente.
Um single-agent com boas tools e instruções resolve surpreendentemente bem. Escale para multi-agent apenas quando:
- O agent tem muitas tools (>15-20) e começa a confundir quando usar cada uma
- As tarefas exigem contextos incompatíveis (ex: tom formal para vendas vs. técnico para debug)
- Você precisa de especialização profunda em domínios distintos
Quando escalar: Manager Pattern
Um agente central (manager) delega tarefas para agentes especializados. É o equivalente ao Orchestrator-Workers da Anthropic, mas a OpenAI enfatiza a autonomia do manager em decidir para quem delegar.
Quando escalar: Decentralized Pattern
Agentes pares que fazem handoff entre si. Não há coordenador central — cada agente decide quando passar a bola.
A diferença chave: no Manager, o coordenador mantém controle. No Decentralized, cada agente é autônomo e faz handoff direto. Use Manager quando precisar de visão global; Decentralized quando os agentes são independentes e o fluxo é linear.
Safety e Guardrails
Esta é provavelmente a seção mais ignorada na prática — e a mais enfatizada pela OpenAI. Safety não é feature, é requisito.
A OpenAI propõe uma defesa em camadas:
Camada 1: Input (antes do agente processar)
- Classifier de relevância: O input é relacionado ao domínio do agente? Filtre spam, tentativas de jailbreak, e pedidos fora de escopo
- Moderação: Use APIs de moderação (OpenAI Moderation, Perspective API) para bloquear conteúdo tóxico ou perigoso
- Rate limiting: Limite chamadas por usuário para prevenir abuso
Camada 2: Processamento (durante a execução)
- PII filtering: Mascare dados sensíveis (CPF, cartão de crédito) antes de enviar ao modelo
- Tool permissions: Nem todo agente deve ter acesso a todas as tools. Princípio do menor privilégio
- Limites de iteração: Cap de loops para evitar que o agente entre em espiral infinita
Camada 3: Output (antes de entregar ao usuário)
- Validação de resposta: A resposta faz sentido? Está no formato esperado?
- Filtro de conteúdo: Remova informações que o agente não deveria revelar (dados internos, prompts do sistema)
- Logging: Registre todas as decisões para auditoria
Human-in-the-Loop
Nem toda decisão deve ser automática. Defina claramente quando escalar para humano:
ESCALATION_RULES = {
"financial": "Qualquer transação > R$500",
"deletion": "Exclusão permanente de dados",
"compliance": "Questões jurídicas ou regulatórias",
"frustrated_user": "Score de sentimento < -0.7",
"low_confidence": "Agente com confidence < 0.6",
"max_retries": "3 tentativas sem resolução"
}
A regra é simples: erre para o lado da cautela. É melhor escalar demais no início e relaxar gradualmente do que o contrário.
Anti-patterns: O que NÃO fazer
Após ver dezenas de implementações de agentes, aqui os erros mais comuns:
1. Over-engineering
Construir um orchestrator-workers para uma tarefa que um único prompt resolve. Cada pattern adiciona latência, custo e pontos de falha. Comece simples e evolua para complexidade.
2. Agentes para tudo
Nem toda automação precisa de um agente. Uma regra de negócio determinística ("se valor > 1000, aprovar manualmente") não precisa de LLM. Use agentes para ambiguidade e contexto, não para lógica binária.
3. Ignorar latência
Cinco patterns em sequência, cada um com 2-3 segundos de LLM, resultam em 15+ segundos de espera. Seu usuário não vai esperar. Meça latência por pattern e otimize ou paralelize.
4. Sem métricas
"Parece funcionar" não é métrica. Você precisa de:
- Taxa de sucesso por tarefa
- Latência p95
- Custo por interação
- Taxa de human-in-the-loop (quando o agente desiste)
5. Prompts frágeis
Depender do LLM "entender" sem estrutura. Sempre use:
- Output schemas (JSON, XML)
- Few-shot examples
- Validação de saída
Métricas: Como saber se seu agente é efetivo
Use este checklist para avaliar sua implementação:
| Métrica | Bom | Ruim | Como medir |
|---|---|---|---|
| Task Success Rate | > 85% | < 60% | Tarefas completadas sem intervenção |
| Latência p95 | < 5s | > 15s | Tempo fim-a-fim por interação |
| Cost per Task | < $0.10 | > $0.50 | Custo de tokens / tarefas completadas |
| Human Escalation | < 10% | > 30% | % de casos que precisam de humano |
| Error Recovery | > 70% | < 40% | % de erros que o agente corrige sozinho |
| User Satisfaction | > 4.0/5 | < 3.0/5 | NPS ou CSAT específico do agente |
Regra de ouro: Se seu agente precisa de humano em mais de 20% dos casos, ele não está pronto para produção. Refine o prompt, adicione exemplos, ou simplifique o escopo.
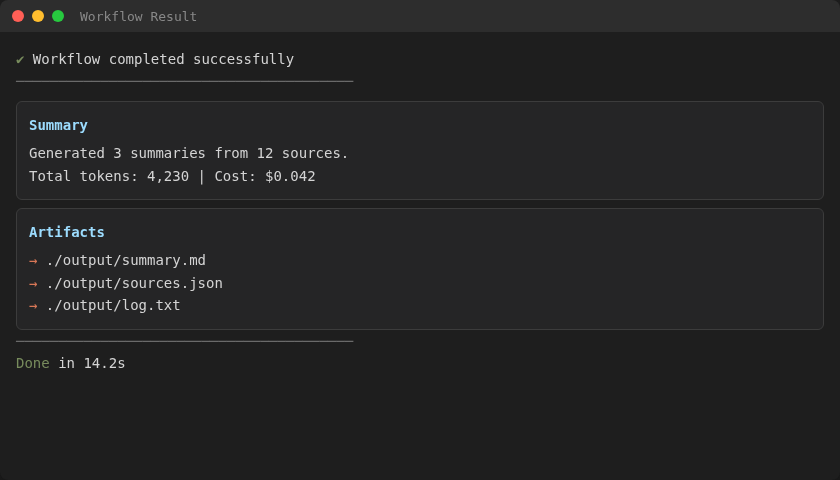
Exemplo de saída de um workflow de agente com resumo, artefatos gerados e tempo de execução.
Conclusão
Ao final deste guia (parte 4 da Trilha) você projeta arquiteturas efetivas com safety — no meu sistema, isso vira agentes que entregam valor real e crescem via método.
Estudar os dois guias lado a lado revelou algo interessante: eles são complementares, não concorrentes.
A Anthropic te dá os patterns de composição — como montar workflows robustos com Prompt Chaining, Routing, Parallelization, Orchestrator-Workers e Evaluator-Optimizer. A OpenAI te dá os fundamentos de produção — os 3 pilares (Modelo, Tools, Instruções), estratégias de safety em camadas, e a disciplina de começar simples.
A tese central é a mesma: comece simples, meça, e adicione complexidade apenas quando os dados justificarem. Um agente efetivo não é o mais sofisticado — é o que resolve o problema do usuário de forma confiável e previsível.
Próximos passos (construa seu sistema ou confie em orientação)
- Acerte os pilares: Modelo capaz, tools bem nomeadas, instruções claras. Sem isso, nenhum pattern salva
- Comece com um agente: Resista à tentação de criar multi-agent antes de provar que um único agente não basta
- Implemente safety desde o dia 1: Classifiers, PII filtering, human-in-the-loop. Não deixe para depois
- Escolha um pattern por vez: Não tente construir um orchestrator-evaluator-router de uma vez
- Meça antes de otimizar: Estabeleça baseline de latência, custo e taxa de sucesso
- Leia os guias originais: Este post é uma síntese prática, mas os originais têm nuances valiosas
Aplique ou aprofunde:
- Context Engineering — próximo na trilha
- Falar comigo no WhatsApp para revisar a arquitetura do seu agente
Post baseado nos guias "Building Effective Agents" da Anthropic e "A Practical Guide to Building AI Agents" da OpenAI, com implementação prática usando Hermes Agent.